Úvod
Hledání chyb plynoucích ze souběžného zpracovávání výpočtů je velmi obtížné, protože se tyto chyby neobjevují předvídatelně. Tato diplomová práce se zabývá plně automatickou detekcí a léčením dvou takových chyb – časově závislých chyb nad daty (data race) a chyb plynoucíc z nesprávné atomicity operací (atomicity violation). Práce prezentuje dva různé algoritmy pro detekci. Jedním z nich je nový algoritmus nazvaný AtomRace, který detekuje časově závislé chyby nad daty jako speciální případ nesprávné atomicity operací. Práce také představuje několik technik pro léčení (opravu) těchto chyb. Následné léčení detekovaných chyb, které probíhá za běhu programu, je založeno na potlačení opakování chyby. Zjednodušeně řečeno, vynucuje správné vykonávání určitých částí kódu. Architektura a algoritmy byly implementovány a otestovány v několika případových studiích včetně dvou reálných komplexních softwarových produktů, které byly poskytnuty firmami IBM a Telefonica.
Studované chyby v souběžnosti
K časově závislé chybě nad daty dochází mezi dvěma vlákny, které přistupují ke sdílené proměnné, tehdy, když alespoň jeden přístup je zápis a mezi vlákny neexistuje žádný explicitní mechanismus synchronizace, který by zajistil, že k těmto přístupům nemůže dojít současně. Výslednou hodnotu proměnné v takovémto případě nelze určit. Časově závislé chyby nad daty se velmi často vyskytují společně s chybami plynoucími z nesprávné atomicity operací. K této chybě dochází, jestliže určitý blok kódu, který pracuje s určitou sdílenou proměnnou a který má být vykonán atomicky, je proložen neserializovatelným přístupem k této proměnné z jiného vlákna. Tato situace je vyobrazena na obrázku [1].

Obrázek 1: Příklad chyby plynoucí z nesprávné atomicity operace.
Na obrázku vidíme příklad, kdy je jeden příkaz vykonáván dvěma různými vlákny souběžně. Vyobrazený kód mění hodnotu počítadla, například počítadla prodaných letenek. Jeden příkaz sold_counter--; je v Javě vyjádřen třemi instrukcemi bytekódu. Díky nesprávné synchronizaci a nešťastnému proložení přístupů je výsledná hodnota proměnné chybná (počítadlo ukazuje, že byla prodána pouze jedna letenka místo dvou). Je evidentní, že se chyba projeví pouze tehdy, když dojde k naznačenému nešťastnému proložení. Velmi řídký výskyt této chyby stěžuje její nalezení. Technologie navržená v této diplomové práci umožňuje detekovat tyto situace a opravovat je při běhu programu.
Navržená technologie
Navržená technologie detekce a léčení výše zmíněných chyb je vyobrazena na obrázku [2]. Proces plně automatické detekce a léčení chyb lze rozdělit do dvou částí. Předzpracování (preprocessing) je prováděno ještě před samotným spuštěním analyzovaného programu. Po spuštění je pak využito dynamické analýzy pro odhalení chyb v souběžnosti a jejich okamžitého opravování za běhu programu.
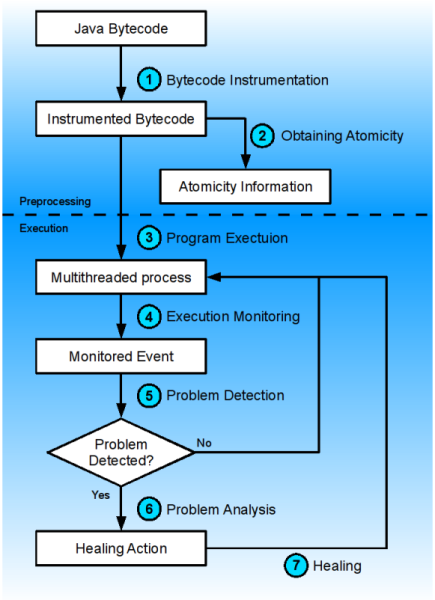
Obrázek 2: Navržená technologie.
Proces detekce a léčení se skládá z těchto sedmi úloh:
Instrumentace bytekódu (Bytecode Instrumentation) – Nástroj pro testování souběžnosti programů ConTest od firmy IBM je využit pro instrumentaci bytekódu. Instrumentace vloží mezi původní instrukce další, které jsou pak využívány pro sledování běhu programu.
Získání atomicity (Obtaining Atomicity) – Statický analýzátor FindBugs je využit k detekci bloků kódu, které by měly být vykonávány atomicky. Pro detekci byly navrženy dva přístupy:
Statická analýza založená na vyhledávání vzorů – Analýza detekuje typické konstrukce v kódu.
Statická analýza založená na určení tzv. access interleaving invariantů – Analýza detekuje dva po sobě následující přístupy ke sdílené proměnné – kandidáty na bloky kódu, které by neměly být nevhodně proloženy. Následně je využito dynamické analýzy k odstranění těch kandidátů, kteří pro daný program neplatí. Tímto přistupem se lze naučit správnou atomicitu programu.
Spuštění programu (Program Execution) – Instrumentovaný kód je spuštěn stejně, jako originální program.
Monitorování programu (Execution Monitoring) – Instrukce vložené během instrumentace umožňují ConTestu sledovat program a předávat tyto informace detektoru ve formě proudu událostí, které popisují chování sledovaného programu. Vložené instrukce dovolují nejen sledovat, ale také ovlivňovat běh programu, čehož se využívá při léčení.
Detekce problému (Problem Detection) – Proud událostí je analyzován algoritmem pro detekci chyb. K tomuto účelu byly implementovány dva algoritmy:
Eraser+ algoritmus – Tento algoritmus je modifikací známého algoritmu Eraser, který se snaží odvodit, jaký zámek je využit pro řízení přístupu k dané sdílené proměnné. Pokud sdílená proměnná není chráněna zámkem, může dojít k časově závislé chybě nad daty. Původní algoritmus byl vylepšen o podporu join synchronizace a upraven tak, aby reflektoval specifika jazyka Java. Tyto úpravy značně snížily počet chybných hlášení o chybách. I přesto algoritmus občas produkuje tato chybná hlášení zejména v případě, kdy je využito jiného druhu synchronizace. Potlačení chybných hlášení je velmi důležité, protože jinak se může stát, že navržený systém začne léčit bezchybný kód.
AtomRace algoritmus – Tento nový algoritmus detekuje časově závislé chyby nad daty jako speciální případ porušení správné atomicity. Vytváří primitivní atomickou sekci kolem každého přístupu ke sdílené proměnné (sekce začíná těsně před přístupem a končí těsně po přístupu). Jestliže se dvě takové primitivní atomické sekce definované nad stejnou sdílenou proměnnou překryjí, časově závislá chyba je detekována. Toto řešení netrpí chybnými hlášeními a navíc podporuje i detekci porušení obecnějších atomických sekcí získaných v bodě 2 během předzpracování.
Analýza problému (Problem Analysis) – Když je problém detekován, systém vytvoří hlášení a uloží ho do souboru s hlášeními. Toto hlášení obsahuje dostatek informací k identifikaci a porozumění důvodů vzniku detekované chyby.
Léčení (Healing) – Časově závislé chyby jsou většinou způsobeny chybějící, nebo chybně použitou synchronizací. Dva způsoby napravení těchto chyb byly vyzkoušeny:
Dodatečná synchronizace – Problematické proměnné je přiřazen nový zámek, který ji má chránit. Zámek je zamknut vždy předtím, než je přistoupeno k problematické proměnné, a odemknut hned po přístupu. Zámek není odemykán mezi přístupy, které mají být vykonány atomicky. Tento přístup vyléčí problém úplně, avšak nové zamykání může způsobit jiný problém plynoucí ze souběžnosti – uváznutí (deadlock).
Legální ovlivňování plánovače – Do programu jsou přidány instrukce, které vynucují přepnutí kontextu, čekání, či mění priority vláken. Vložení těchto instrukcí si klade za cíl pozměnit prokládání vláken tak, aby nebylo potřeba chybně implementované synchronizace. Tento přístup nevyléčí problém úplně, ale snižuje pravděpodobnost projevení chyby. Experimenty ukázaly, že tento přístup v některých případech funguje a problém vyléčí.
Experimentální výsledky
Navržená technologie pro dynamickou detekci a léčení časově závislých chyb byla testována na třech případových studiích, které se lišily ve velikosti a podmínkách, za jakých k chybám dochází. První studií byl jednoduchý a známý příklad symulující práci banky od firmy Sun. Tento velmi jednoduchý program byl vybrán pro pochopení a testování vlastností jednotlivých léčících přístupů. Dvě další studie byly reálné softwarové produkty firem IBM a Telefonica.
Implementovaný prototyp našel v těchto programech nejen známé chyby, ale i několik dříve neznámých časově závislých chyb, které byly nahlášeny vývojářům a opraveny. Tento úspěch při detekci byl způsoben novou kombinací algoritmů pro dynamickou analýzu s technikou vkládání hluku, která je dostupná v nástroji ConTest. Technika vkládání hluku do běhu programu umožňuje měnit scénáře proložení vláken a umožňuje tak sledovat při opakovaných testech různé proložení. Během práce na této diplomové práci byly navrhnuty nové heuristiky pro vkládání tohoto hluku. Nové heuristiky ještě zvýšily efektivitu odhalování časově závislých chyb.
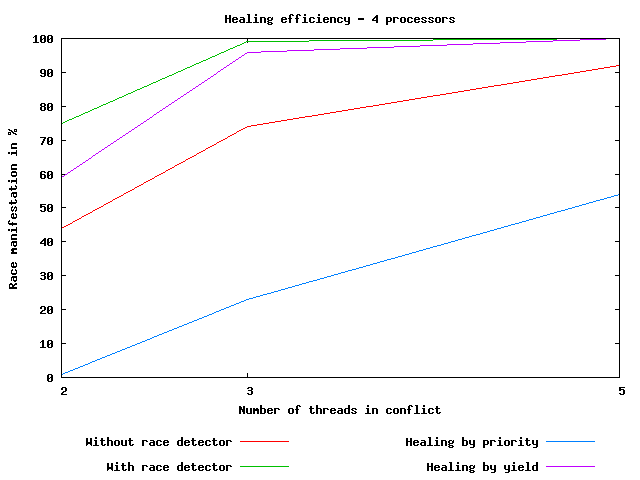
Obrázek 3: Efektivita léčení.
Vlastnosti některých navržených technik pro léčení lze vidět v grafu na obrázku [3]. Graf vyjadřuje efektivnost léčení v příkladu simulace banky. Červená čára znázorňuje pravděpodobnost, že se chyba projeví, když je aplikace spuštěna bez navržené technologie. Zelená čára znázorňuje pravděpodobnost projevu, když je aplikace spuštěna a sledována algoritmem pro detekci chyb. Pravděpodobnost projevu chyby je v tomto případě vyšší, protože vložené instrukce ConTestu a detektoru zvětšují časové okno, kdy může dojít k projevu chyby. Modrá čára znázorňuje situaci, kdy bylo aplikováno léčení založené na ovlivňování plánovače. Je vidět, že v případě, kdy mohlo dojít k chybě jen mezi dvěma vlákny, léčení pomohlo a chyba se neprojevila. Není překvapením, že léčení využívající techniku dodatečné synchronizace chybu vyléčí vždy, jak to znázorňuje fialová čára.
Shrnutí
Přínos práce k současnému stavu boje s časově závislými chybami nad daty lze spatřit ve třech různých bodech. Práce prezentuje nový algoritmus AtomRace pro dynamickou detekci časově závislých chyb nad daty a chyb plynoucích z nesprávné atomicity operací. Algoritmus je porovnán s upraveným dobře známým algoritmem Eraser. AtomRace neprodukuje chybná hlášení, podporuje všechny možné typy synchronizace a je schopen detekovat i porušení nesprávné atomicity operací. Dalším přínosem je otestování a využití kombinace algoritmů pro dynamickou detekci s technikou pro vkládání hluku. Ukázalo se, že zvolení vhodné heuristiky pro vkládání hluku značně zvyšuje efektivitu algoritmů detekujících časově závislé chyby. Třetím přínosem je samotné navržení a otestování různých technik pro léčení časově závislých chyb nad daty během provádění programu. Některé z těchto technik byly schopny vynutit správné provádění jinak chybného kódu.